High Availability Setup (Resolve DB Deadlocks)
Resolve any Database Deadlocks you see in high traffic by using this setup
What causes the problem?
LiteLLM writes UPDATE and UPSERT queries to the DB. When using 10+ instances of LiteLLM, these queries can cause deadlocks since each instance could simultaneously attempt to update the same user_id, team_id, key etc.
How the high availability setup fixes the problem
- All instances will write to a Redis queue instead of the DB.
- A single instance will acquire a lock on the DB and flush the redis queue to the DB.
How it works
Stage 1. Each instance writes updates to redis
Each instance will accumlate the spend updates for a key, user, team, etc and write the updates to a redis queue.
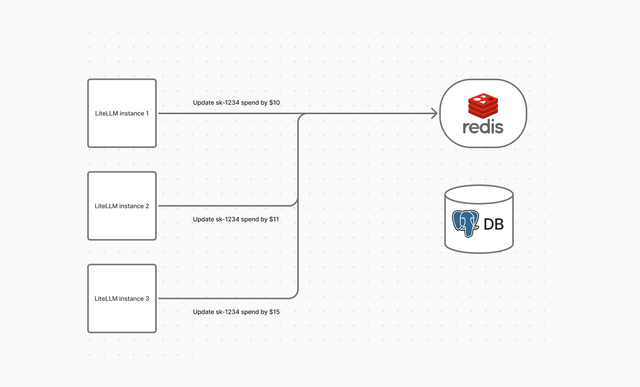
Each instance writes updates to redis
Stage 2. A single instance flushes the redis queue to the DB
A single instance will acquire a lock on the DB and flush all elements in the redis queue to the DB.
- 1 instance will attempt to acquire the lock for the DB update job
- The status of the lock is stored in redis
- If the instance acquires the lock to write to DB
- It will read all updates from redis
- Aggregate all updates into 1 transaction
- Write updates to DB
- Release the lock
- Note: Only 1 instance can acquire the lock at a time, this limits the number of instances that can write to the DB at once
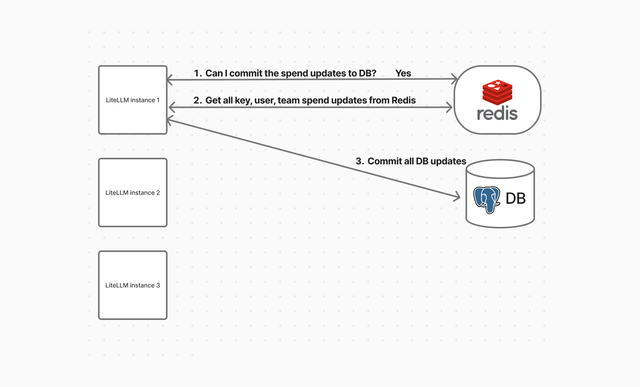
A single instance flushes the redis queue to the DB
Usage
Required components
- Redis
- Postgres
Setup on LiteLLM config
You can enable using the redis buffer by setting use_redis_transaction_buffer: true in the general_settings section of your proxy_config.yaml file.
Note: This setup requires litellm to be connected to a redis instance.
general_settings:
use_redis_transaction_buffer: true
litellm_settings:
cache: True
cache_params:
type: redis
supported_call_types: [] # Optional: Set cache for proxy, but not on the actual llm api call